

Vision4Blind
Highlights
- Vision-Language Models
- 2D/3D Scene Understanding
- Object and Material Recognition
- Walkable Path Suggestion and Obstacle Avoidance
- Social Interaction Support
- Wearable Smart Devices (Vision Glasses, AR/VR Headsets, Smart Belts)
- Acoustic and Haptic Interfaces
| Author | Title | Source |
|---|---|---|
Xin Jiang, Junwei Zheng, Ruiping Liu, Jiahang Li, Jiaming Zhang, Sven Matthiesen, Rainer Stiefelhagen |
ATBench: Benchmarking Vision-Language Models for Human-centered Assistive Technology | IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2025, PDF. |
H. Chen, Y. Zhang, K. Yang, M. Martinez, K. Müller, R. Stiefelhagen |
Can We Unify Perception and Localization in Assisted Navigation? An Indoor Semantic Visual Positioning System for Visually Impaired People | In International Conference on Computers Helping People with Special Needs (ICCHP), Online, September 2020, pdf |
M. Martinez, K. Yang, A. Constantinescu, R. Stiefelhagen |
Helping the Blind to Get through COVID-19: Social Distancing Assistant Using Real-Time Semantic Segmentation on RGB-D Video | Sensors, September 2020, pdf |
W. Hu, K. Wang, K. Yang, R. Cheng, Y. Ye, L. Sun, Z. Xu |
A Comparative Study in Real-Time Scene Sonification for Visually Impaired People | Sensors, June 2020, pdf |
M. Martinez, A. Roitberg, D. Koester, B. Schauerte, R. Stiefelhagen |
Using Technology Developed for Autonomous Cars to Help Navigate Blind People | ICCV Workshop on Assistive Computer Vision and Robotics (ACVR), Venice, Italy, October 2017, pdf |
T. Wörtwein, B. Schauerte, K. Mueller, R. Stiefelhagen |
Interactive Web-based Image Sonification for the Blind | International Conference on Multimodal Interaction (ICMI), Seattle, Washington, USA, November, 2015 |
B. Schauerte, T. Wörtwein, R. Stiefelhagen |
A Web-based Platform for Interactive Image Sonification | Accessible Interaction for Visually Impaired People (AI4VIP), Stuttgart, Germany, September, 2015 |
B. Schauerte, D. Koester, M. Martinez, R. Stiefelhagen |
Way to Go! Detecting Open Areas Ahead of a Walking Person | ECCV Workshop on Assistive Computer Vision and Robotics (ACVR), Zurich, Switzerland, September, 2014 |
D. Koester, B. Schauerte, R. Stiefelhagen |
Accessible Section Detection for Visual Guidance | IEEE Workshop on Multimodal and Alternative Perception for Visually Impaired People (MAP4VIP ) In Conjunction with ICME 2013 (pdf |bib ) |
B. Schauerte, M. Martinez, A. Constantinescu, R. Stiefelhagen |
An Assistive Vision System for the Blind that Helps Find Lost Things | International Conference on Computers Helping People with Special Needs (ICCHP), Linz, Austria, July, 2012 |
J. Zheng, J. Zhang, K. Yang, K. Peng, R. Stiefelhagen |
MateRobot: Material Recognition in Wearable Robotics for People with Visual Impairments | 2024 IEEE International Conference on Robotics and Automation (ICRA), DOI. |
R. Liu, J. Zhang, K. Peng, J. Zheng, K. Cao, Y. Chen, K. Yang, R. Stiefelhagen |
Open Scene Understanding: Grounded Situation Recognition Meets Segment Anything for Helping People with Visual Impairments | International Workshop on Assistive Computer Vision and Robotics (ACVR) with IEEE/CVF International Conference on Computer Vision (ICCV), 2023. DOI. |
Vision-Language Models for Assistitve Technology

ATBench is a framework designed to benchmark Vision-Language Models (VLMs) specifically for applications in human-centered assistive technology. The work discusses how these models can significantly enhance the capabilities and usability of assistive technologies, particularly for persons with visual impairments (PVIs). By integrating multi-modal information, ATBench aims to provide comprehensive assistance tailored to the needs of users.
- ATBench emphasizes the importance of combining visual and language data to enhance the performance of assistive technologies. This integration is essential for offering users a more intuitive and effective interaction with their environments, allowing models to understand context better and generate more relevant responses.
- The framework introduces a series of new metrics specifically designed to evaluate VLMs in the context of assistive technology. These metrics not only assess the accuracy of responses but also consider the usability and user satisfaction aspects, which are crucial for real-world applications in assisting users.
- ATBench aims to bridge the gap between technical performance and practical usability by testing models on tasks that closely mimic the everyday challenges faced by PVIs. This focus ensures that the developed VLMs are not only theoretically sound but are also practically applicable in assisting real users, thereby enhancing their daily lives.
Scene Understanding
People with Visual Impairments (PVI) often have difficulty interpreting their surroundings correctly due to the lack of visual cues. Understanding a scene through tactile exploration proves insufficient and potentially hazardous. Often people need to recognize the whole scene at first glance, then gaze at each object, sort out their relationships, and react to the scene.
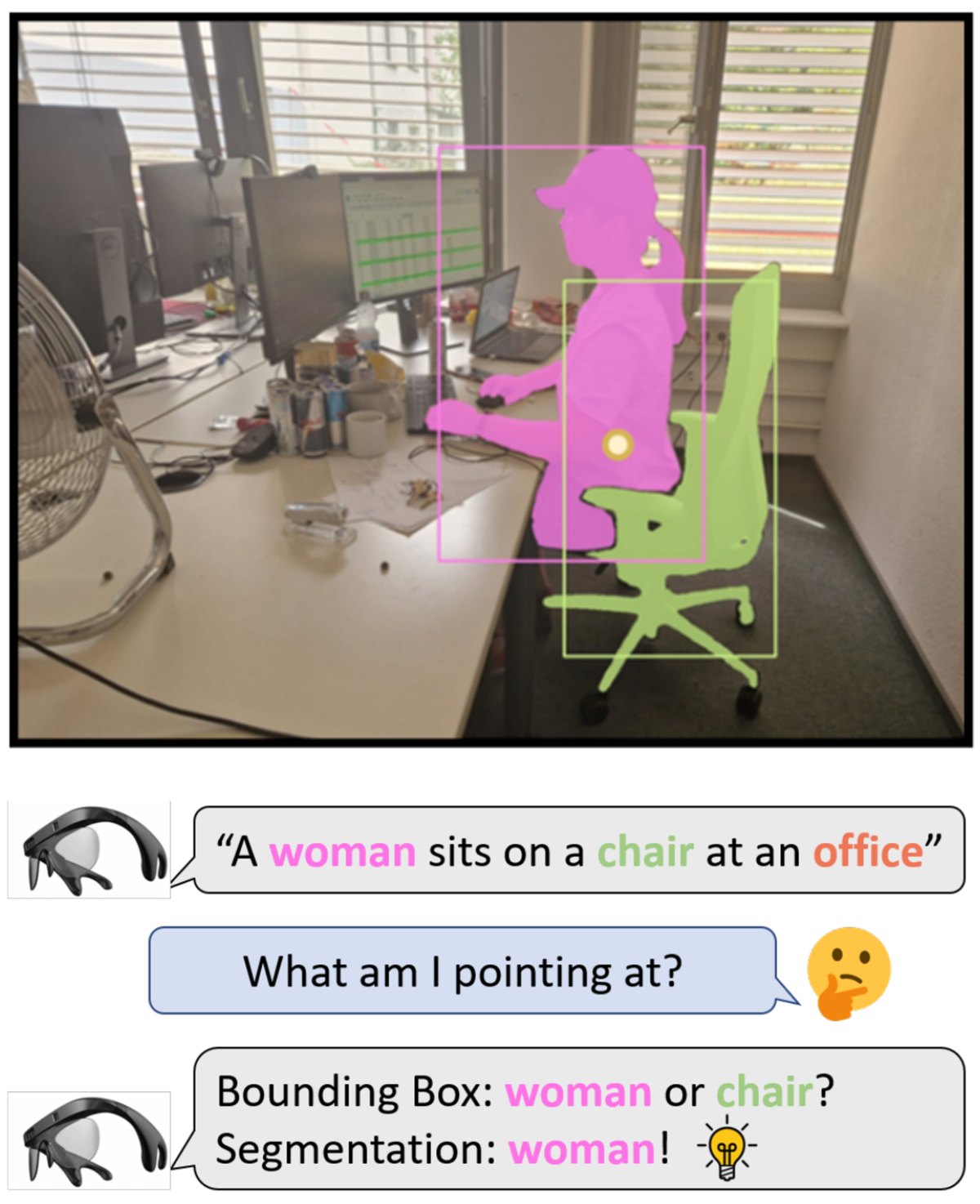
We explore scene understanding for helping PVI. In this work, we design an Open Scene Understanding (OpenSU) system which consists of Grounded Situation Recognition (GSR) and Segment Anything (SAM), allowing PVI to perceive the entirety of the scene and retrieve object information in a specified direction.
Grounded situation recognition captures the activity (e.g., sitting), nouns (e.g., woman, chair, office) related to the roles (Agent, Item, Place), and the bounding boxes of the objects. The caption template is “An Agent sits on an Item at a Place”, so the image caption of the verb sitting is “A woman sits on a chair at an office”. SAM uses bounding boxes as prompts to generate the segmentation masks. According to application interaction, potential region indication methods (e.g., fingertip, head pose, laser pointer) can be used to specify a region of interest, and the information can be reported to the user via bone-conducting earphones of wearable systems.
Object and Material Recognition
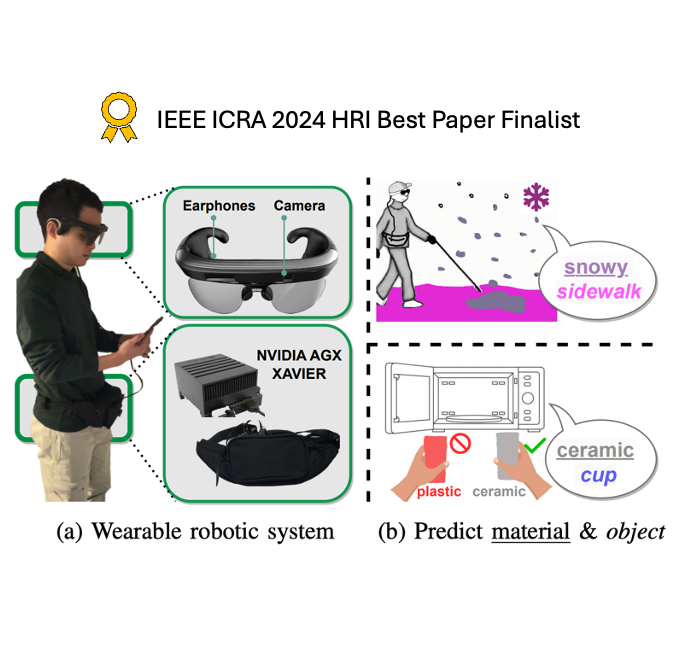
MateRobot is a wearable robotic system aimed at assisting people with visual impairments (PVI) by providing them with the ability to recognize various materials through visual cues. This technology represents a significant advancement in improving the autonomy and mobility of individuals with visual impairments, enabling them to interact more effectively with their environment.
The research demonstrated that it is feasible for this system to accurately identify material properties using advanced machine learning techniques. The ultimate goal is to enhance the functionality of wearable robotics by integrating material recognition capabilities, thereby enriching the sensory experiences of users.
-
MateRobot utilizes a vision-based approach to identify different materials, which is essential for helping users understand their surroundings and make informed decisions.
-
The system is designed to be user-friendly for PVI individuals, focusing on improving their daily life by providing real-time feedback about the materials they encounter.
-
The research employs state-of-the-art image segmentation algorithms that increase the accuracy of material recognition.
Navigation and Obstacle Avoidance

We develop a mobility and navigational aid system for visually impaired persons, i.e. blind persons or persons with low vision. The system should enable visually impaired persons to navigate safely in an unknown terrain. It uses computer vision methods to detect landmarks, obstacles and free ground surface in front of the user. Acoustic as well as haptic interfaces (e.g. vibrating elements) are used to give information to the user. We have already created a prototype to this end and develop the system in a user-centered way, which is made possible by our tight cooperation with KIT Center for Digital Accessibility and Assistive Technolgoy (ACCESS∂KIT).
In the long term, we wish to allow visually impaired people to move around and to find their way safely on their own in a new environment, such as an unknown city or any other urban or rural environment. In the short term, our goal is to build a mobile system that helps visually impaired students to safely explore our university campus.
Our goal is to build a mobile assistive system to support the mobility of visually impaired people in various ways:
- provide orientation and navigation information (like GPS navigation systems)
- warn user before obstacles, both on the ground as well as high/low hanging obstacles
- plan a route beforehand, i.e., before a user can reach it with the white cane, with respect to the current situation, e.g., detect accessible section and obstacles along the path
- provide additional information about "the scene", e.g., type of intersection, walkway, people or cyclists approaching or oncoming traffic
- create situation specific "modules", e.g., crossing an inaccessible road intersection (button location, traffic light detection, anti-veering), help with zebra crossings, locating building entries and many others.