

Action Recognition
Highlights
Human-object interaction detection
Human–Object Interaction (HOI) detection is a computer-vision task that identifies and classifies interactions between people and objects in images or videos. It simultaneously locates humans, objects, and the actions linking them, generating subject-verb-object triples such as (person, ride, bicycle) or (hand, grasp, cup). Recent approaches leverage convolutional backbones and attention mechanisms to model spatial cues and contextual relations, achieving end-to-end prediction of interaction triplets with confidence scores. HOI detection underpins applications in visual search, assistive robotics, surveillance, and augmented reality. We explored robust HOI detection by releasing RoHOI—the first benchmark featuring 20 realistic corruptions—markedly boosts model resilience to environmental variability, occlusion and noise. we are now exploring a unified framework that shares representations to perform HOI detection and short-horizon anticipation in one pass; and we are also exploring model to detect anomalous HOI patterns and forecast risky interactions before they occur.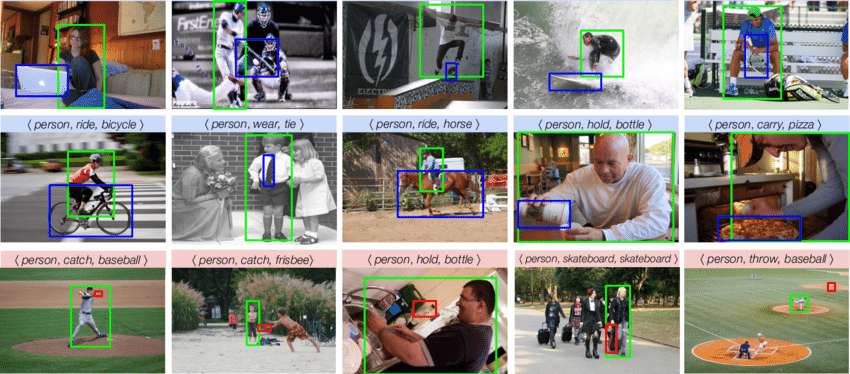
Hand-object interaction detection
Hand–Object Interaction (Hand-OI) detection is a computer-vision task that identifies and localizes the fine-grained manipulations a person’s hands perform on nearby objects, producing triplets such as (left-hand, grasp, cup) or (right-hand, swipe, phone). Unlike general Human–Object Interaction detection, which considers whole-body actions, Hand-OI must resolve finger articulation, contact regions, and subtle pose changes; models therefore rely on high-resolution hand keypoints, depth or contact cues, and attention mechanisms that focus on the hand–object boundary.

Human action segmentation

Video-based Human Action Recognition
Video-based human action recognition is a computer vision task that involves identifying and classifying human actions from video data. It leverages spatial and temporal features to understand motion patterns and contextual cues. Deep learning models, especially convolutional and recurrent neural networks, are commonly used to extract meaningful representations from video sequences. This technology has wide applications in surveillance, healthcare, human-computer interaction, and robotics.
Referring Fine-grained Human Action Recognition
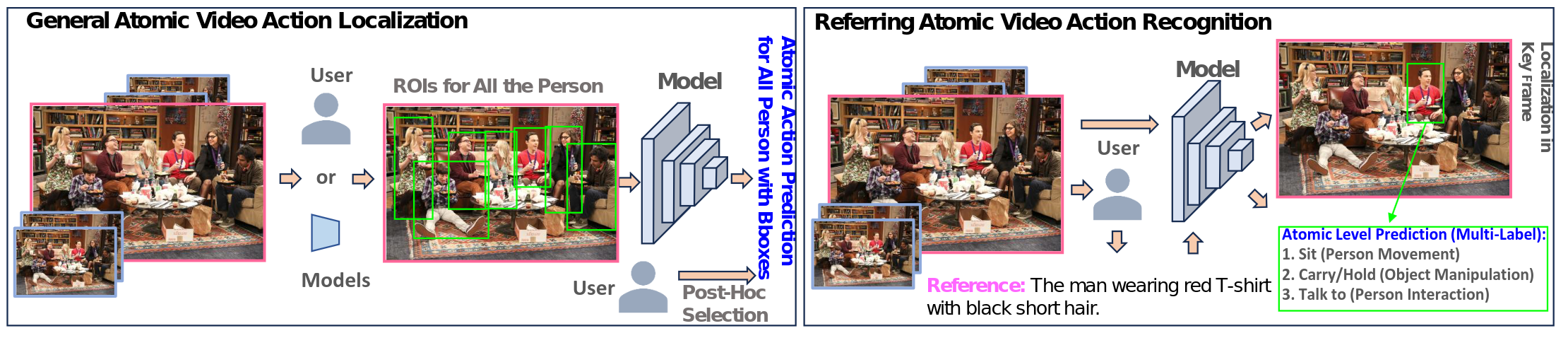
Video-based Activated Muscle Group Prediction
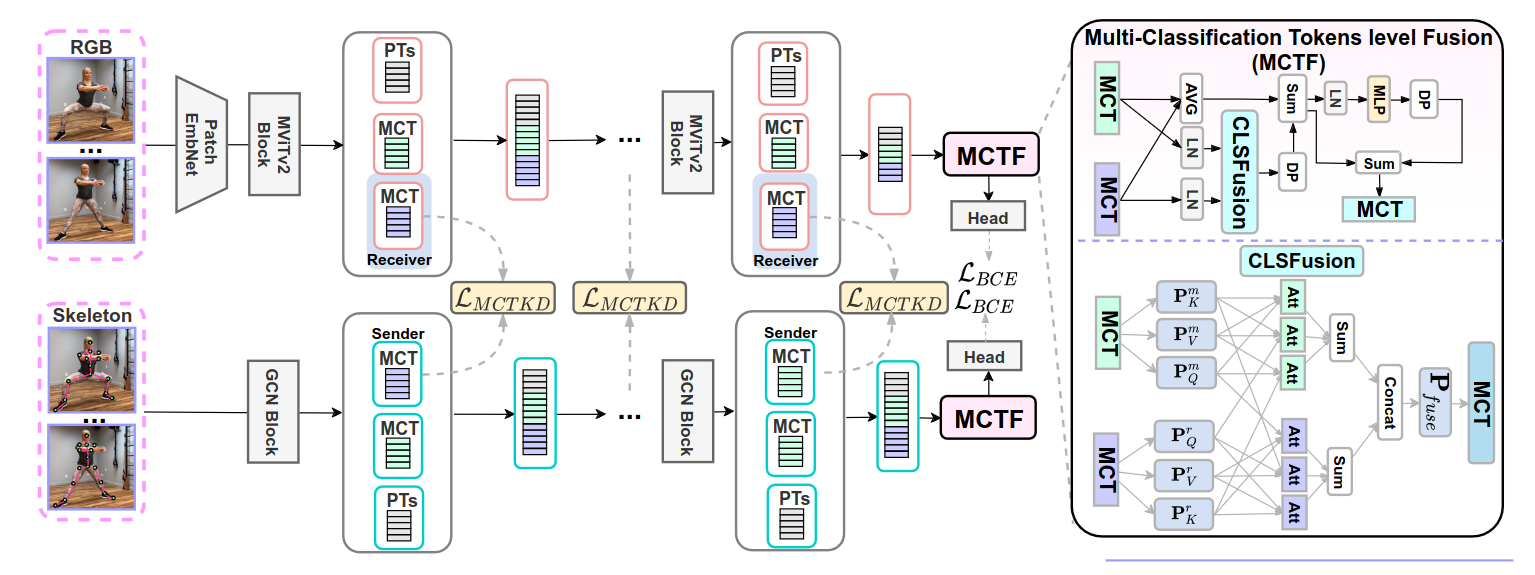
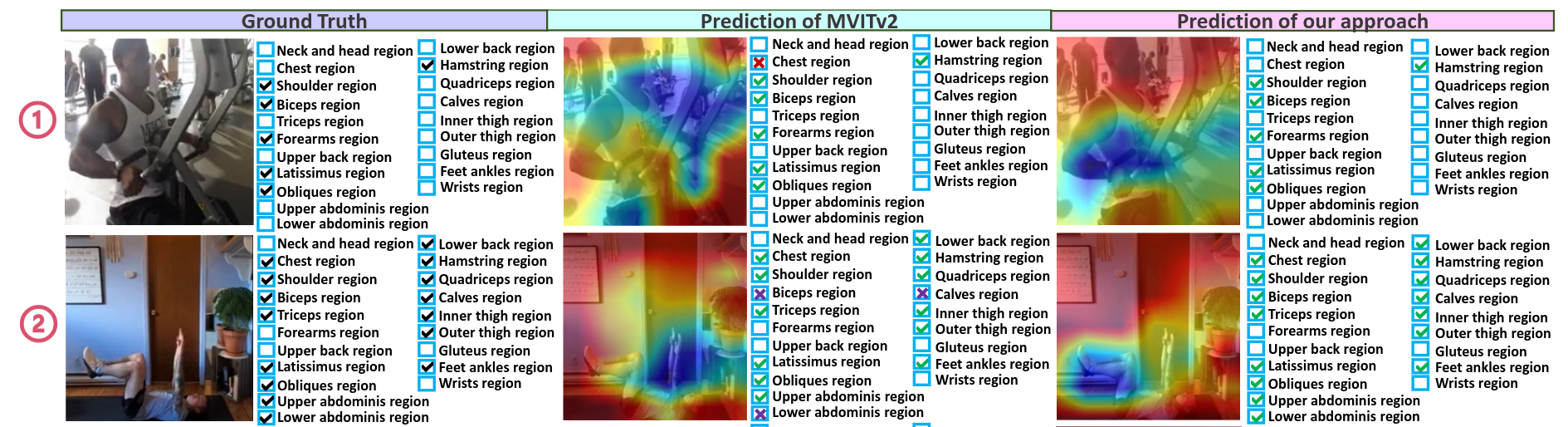
we tackle the new task of video-based Activated Muscle Group Estimation (AMGE) aiming at identifying active muscle regions during physical activity in the wild. To this intent, we provide the MuscleMap dataset featuring >15K video clips with 135 different activities and 20 labeled muscle groups. This dataset opens the vistas to multiple video-based applications in sports and rehabilitation medicine under flexible environment constraints. The proposed MuscleMap dataset is constructed with YouTube videos, specifically targeting High-Intensity Interval Training (HIIT) physical exercise in the wild. To make the AMGE model applicable in real-life situations, it is crucial to ensure that the model can generalize well to numerous types of physical activities not present during training and involving new combinations of activated muscles. To achieve this, our benchmark also covers an evaluation setting where the model is exposed to activity types excluded from the training set. Our experiments reveal that the generalizability of existing architectures adapted for the AMGE task remains a challenge. Therefore, we also propose a new approach, TransM3E, which employs a multi-modality feature fusion mechanism between both the video transformer model and the skeleton-based graph convolution model with novel cross-modal knowledge distillation executed on multi-classification tokens. The proposed method surpasses all popular video classification models when dealing with both, previously seen and new types of physical activities.
Video-based Driver Activity Recognition
We introduce a novel framework designed to enhance the recognition of secondary driver behaviors, which are critical for the development of Advanced Driving Assistance Systems (ADAS). Traditional models often struggle with generalizing across different sensor setups and recognizing underrepresented activities.
The proposed TransDARC framework demonstrates significant performance improvements over existing methods on the Drive&Act benchmark, achieving higher accuracy in both fine-grained and coarse driver activity recognition tasks. The authors also provide qualitative analyses, such as t-SNE visualizations, to illustrate the effectiveness of their latent space calibration in creating more distinct and well-separated feature clusters. These results suggest that TransDARC offers a promising solution for enhancing the robustness and applicability of driver activity recognition systems in real-world scenarios.
![]()
Skeleton-based Human Action Recognition
Skeleton-based human action recognition focuses on analyzing the movement of human joints and bones represented as skeleton sequences. It captures the structural and temporal dynamics of body motion, making it robust to variations in appearance, background, and lighting. Graph-based neural networks, especially graph convolutional networks (GCNs), are commonly used to model the spatial-temporal relationships between joints. This approach is widely used in surveillance, sports analysis, healthcare, and human-robot interaction.
Open-set Skeleton-based Human Action Recognition
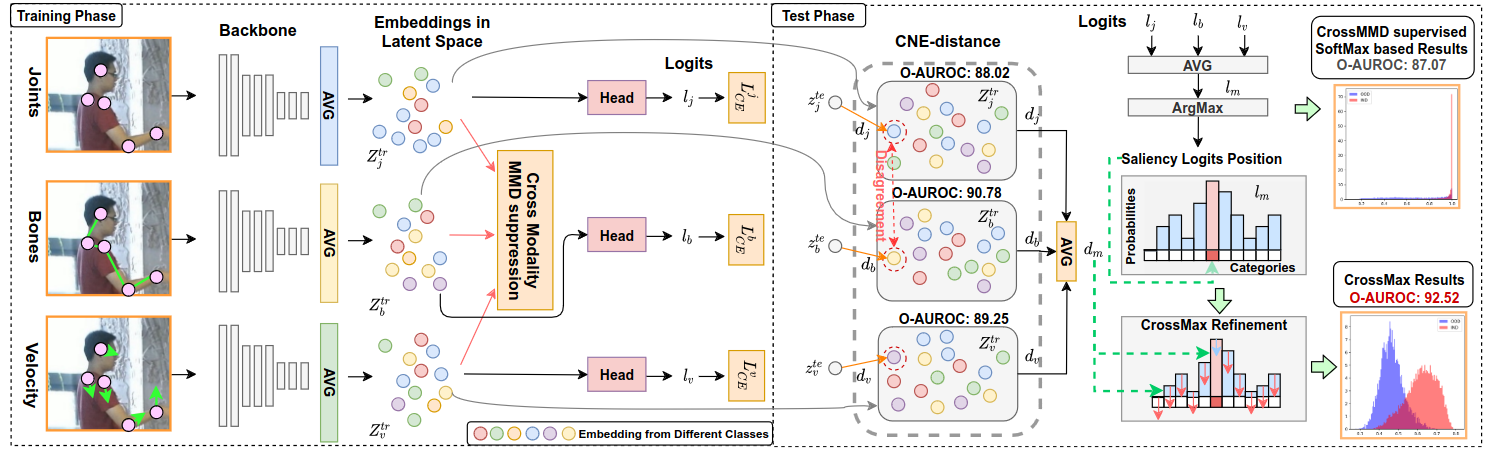
In real-world scenarios, human actions often fall outside the distribution of training data, making it crucial for models to recognize known actions and reject unknown ones. However, using pure skeleton data in such open-set conditions poses challenges due to the lack of visual background cues and the distinct sparse structure of body pose sequences. In this paper, we tackle the unexplored Open-Set Skeleton-based Action Recognition (OS-SAR) task and formalize the benchmark on three skeleton-based datasets. We assess the performance of seven established open-set approaches on our task and identify their limits and critical generalization issues when dealing with skeleton information. To address these challenges, we propose a distance-based cross-modality ensemble method that leverages the cross-modal alignment of skeleton joints, bones, and velocities to achieve superior open-set recognition performance. We refer to the key idea as CrossMax - an approach that utilizes a novel cross-modality mean max discrepancy suppression mechanism to align latent spaces during training and a cross-modality distance-based logits refinement method during testing. CrossMax outperforms existing approaches and consistently yields state-of-the-art results across all datasets and backbones.
Unsupervised Skeleton-based Human Action Recognition
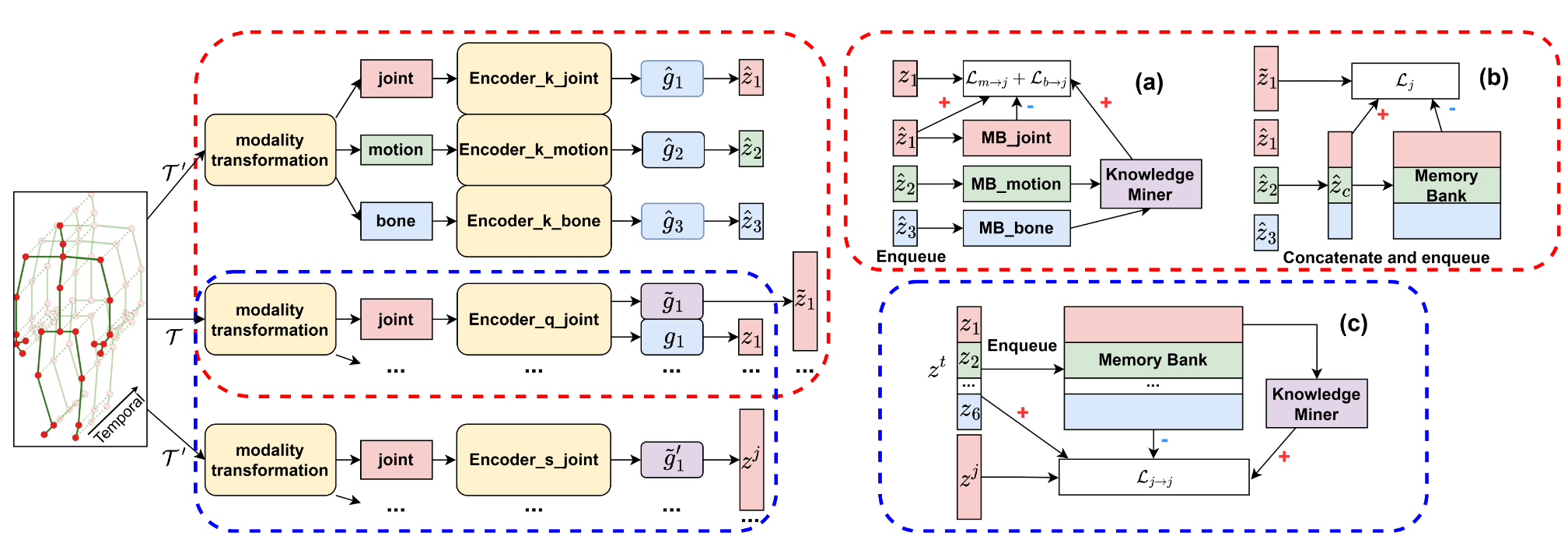
Self-supervised representation learning for human action recognition has developed rapidly in recent years. Most of the existing works are based on skeleton data while using a multi-modality setup. These works overlooked the differences in performance among modalities, which led to the propagation of erroneous knowledge between modalities while only three fundamental modalities, i.e., joints, bones, and motions are used, hence no additional modalities are explored.
We have proposed an Implicit Knowledge Exchange Module (IKEM) which alleviates the propagation of erroneous knowledge between low-performance modalities. Then, we further propose three new modalities to enrich the complementary information between modalities. Finally, to maintain efficiency when introducing new modalities, we propose a novel teacher-student framework to distill the knowledge from the secondary modalities into the mandatory modalities considering the relationship constrained by anchors, positives, and negatives, named relational cross-modality knowledge distillation.
Skeleton-based Human Action Recognition under Noisy Labels
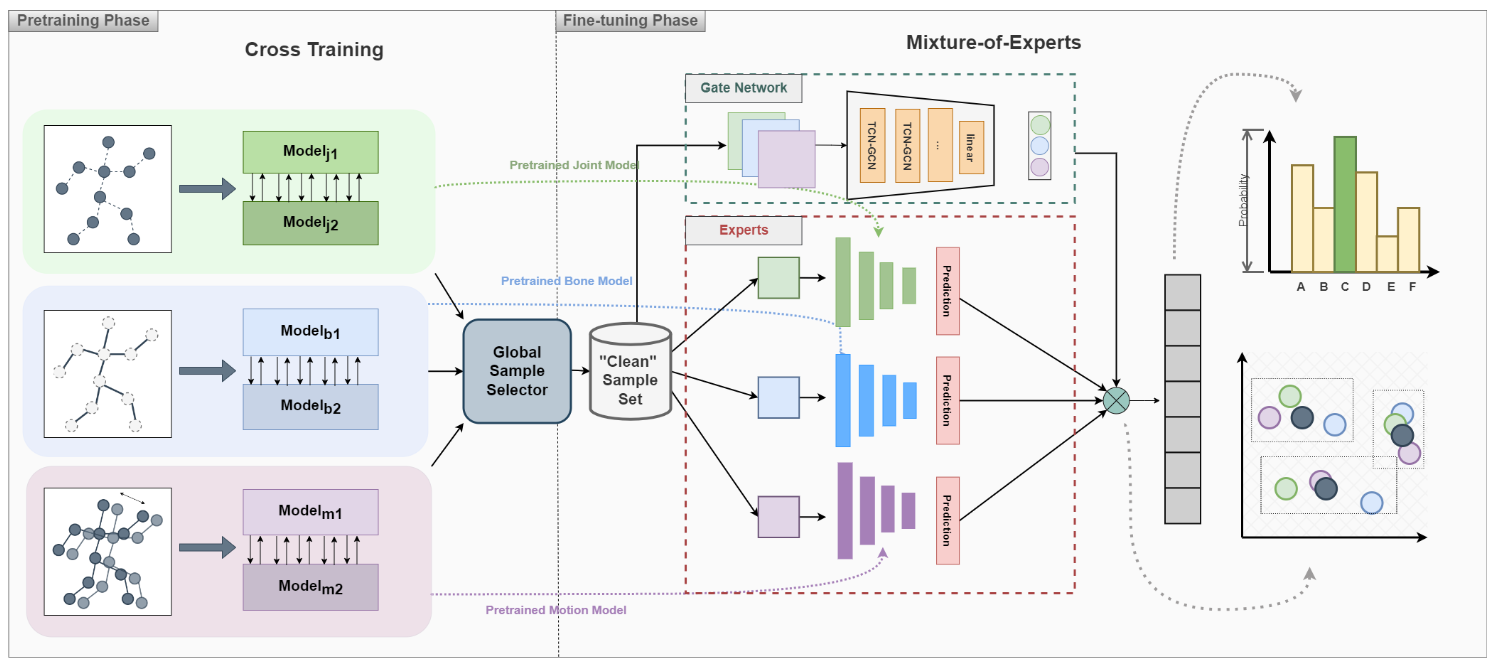
Understanding human actions from body poses is critical for assistive robots sharing space with humans in order to make informed and safe decisions about the next interaction. However, precise temporal localization and annotation of activity sequences is time-consuming and the resulting labels are often noisy. If not effectively addressed, label noise negatively affects the model's training, resulting in lower recognition quality. Despite its importance, addressing label noise for skeleton-based action recognition has been overlooked so far. In this study, we bridge this gap by implementing a framework that augments well-established skeleton-based human action recognition methods with label-denoising strategies from various research areas to serve as the initial benchmark. Observations reveal that these baselines yield only marginal performance when dealing with sparse skeleton data. Consequently, we introduce a novel methodology, NoiseEraSAR, which integrates global sample selection, co-teaching, and Cross-Modal Mixture-of-Experts (CM-MOE) strategies, aimed at mitigating the adverse impacts of label noise. Our proposed approach demonstrates better performance on the established benchmark, setting new state-of-the-art standards.
One-shot Skeleton-based Human Action Recognition
Occlusions are universal disruptions constantly present in the real world. Especially for sparse representations, such as human skeletons, a few occluded points might destroy the geometrical and temporal continuity critically affecting the results. Yet, the research of data-scarce recognition from skeleton sequences, such as one-shot action recognition, does not explicitly consider occlusions despite their everyday pervasiveness. In this work, we explicitly tackle body occlusions for Skeleton-based One-shot Action Recognition (SOAR). We mainly consider two occlusion variants: 1) random occlusions and 2) more realistic occlusions caused by diverse everyday objects, which we generate by projecting the existing IKEA 3D furniture models into the camera coordinate system of the 3D skeletons with different geometric parameters. We leverage the proposed pipeline to blend out portions of skeleton sequences of the three popular action recognition datasets and formalize the first benchmark for SOAR from partially occluded body poses. Another key property of our benchmark are the more realistic occlusions generated by everyday objects, as even in standard recognition from 3D skeletons, only randomly missing joints were considered. We re-evaluate existing state-of-the-art frameworks for SOAR in the light of this new task and further introduce Trans4SOAR - a new transformer-based model which leverages three data streams and mixed attention fusion mechanism to alleviate the adverse effects caused by occlusions. While our experiments demonstrate a clear decline in accuracy with missing skeleton portions, this effect is smaller with Trans4SOAR, which outperforms other architectures on all datasets.
![]()
| Author | Title | Source |
|---|---|---|
Kunyu Peng, Cheng Yin, Junwei Zheng, Ruiping Liu, David Schneider, Jiaming Zhang, Kailun Yang, M. Saquib Sarfraz, Rainer Stiefelhagen, Alina Roitberg |
Navigating Open Set Scenarios for Skeleton-Based Action Recognition | AAAI2024 |
Kunyu Peng, David Schneider, Alina Roitberg, Kailun Yang, Jiaming Zhang, Chen Deng, Kaiyu Zhang, M. Saquib Sarfraz, Rainer Stiefelhagen |
Towards Video-based Activated Muscle Group Estimation in the Wild | ACMMM2024 |
Kunyu Peng, Alina Roitberg, Kailun Yang, Jiaming Zhang, Rainer Stiefelhagen |
Should I take a walk? Estimating Energy Expenditure from Video Data | CVPRW2022 |
Kunyu Peng, Jia Fu, Kailun Yang, Di Wen, Yufan Chen, Ruiping Liu, Junwei Zheng, Jiaming Zhang, M. Saquib Sarfraz, Rainer Stiefelhagen, Alina Roitberg |
Referring Atomic Video Action Recognition | ECCV2024 |
Yiping Wei, Kunyu Peng, Alina Roitberg, Jiaming Zhang, Junwei Zheng, Ruiping Liu, Yufan Chen, Kailun Yang, Rainer Stiefelhagen |
Elevating Skeleton-Based Action Recognition with Efficient Multi-Modality Self-Supervision | ICASSP2024 |
Kunyu Peng, Alina Roitberg, Kailun Yang, Jiaming Zhang, Rainer Stiefelhagen |
TransDARC: Transformer-based driver activity recognition with latent space feature calibration | IROS2022 |
Yi Xu, Kunyu Peng, Di Wen, Ruiping Liu, Junwei Zheng, Yufan Chen, Jiaming Zhang, Alina Roitberg, Kailun Yang, Rainer Stiefelhagen |
Skeleton-Based Human Action Recognition with Noisy Labels | IROS2024 |
Kunyu Peng, Alina Roitberg, Kailun Yang, Jiaming Zhang, Rainer Stiefelhagen |
Delving Deep into One-Shot Skeleton-based Action Recognition with Diverse Occlusions | TMM2023 |